

If The Relocation Register Holds The Value -83968.how Many Kilobytes Was It Moved?
Main Memory
References:
- Abraham Silberschatz, Greg Gagne, and Peter Baer Galvin, "Operating Organisation Concepts, Ninth Edition ", Chapter 8
8.one Groundwork
- Obviously retention accesses and memory management are a very important part of modern figurer operation. Every instruction has to be fetched from retention before it tin be executed, and near instructions involve retrieving information from memory or storing data in memory or both.
- The advent of multi-tasking OSes compounds the complexity of memory direction, considering because equally processes are swapped in and out of the CPU, and then must their code and information exist swapped in and out of retention, all at high speeds and without interfering with whatever other processes.
- Shared memory, virtual retentiveness, the classification of memory as read-but versus read-write, and concepts similar copy-on-write forking all further complicate the issue.
eight.1.i Basic Hardware
- It should be noted that from the memory fries indicate of view, all memory accesses are equivalent. The memory hardware doesn't know what a particular part of memory is beingness used for, nor does it care. This is virtually truthful of the Os likewise, although not entirely.
- The CPU can only access its registers and main retentiveness. It cannot, for example, make direct access to the hard drive, so whatever data stored in that location must starting time be transferred into the main retentivity chips earlier the CPU tin can work with information technology. ( Device drivers communicate with their hardware via interrupts and "memory" accesses, sending short instructions for instance to transfer data from the hard drive to a specified location in main memory. The disk controller monitors the bus for such instructions, transfers the data, and then notifies the CPU that the data is in that location with another interrupt, but the CPU never gets direct access to the disk. )
- Retentiveness accesses to registers are very fast, generally one clock tick, and a CPU may be able to execute more than one machine instruction per clock tick.
- Memory accesses to main memory are comparatively slow, and may take a number of clock ticks to complete. This would require intolerable waiting by the CPU if it were not for an intermediary fast memory cache built into almost modern CPUs. The basic idea of the cache is to transfer chunks of retentivity at a fourth dimension from the main memory to the enshroud, then to access individual memory locations one at a time from the cache.
- User processes must be restricted so that they but admission memory locations that "vest" to that particular process. This is normally implemented using a base annals and a limit register for each procedure, as shown in Figures eight.one and 8.two below. Every memory admission made by a user process is checked against these two registers, and if a memory admission is attempted outside the valid range, so a fatal error is generated. The OS obviously has access to all existing memory locations, as this is necessary to swap users' code and information in and out of memory. It should also be obvious that irresolute the contents of the base of operations and limit registers is a privileged activity, immune simply to the Os kernel.
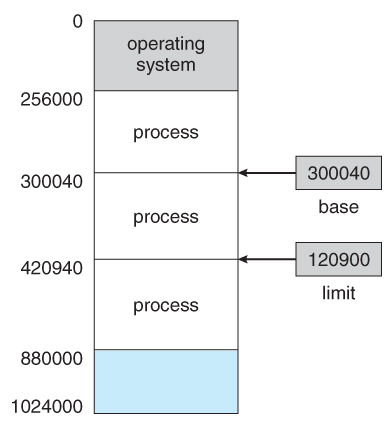
Figure eight.1 - A base and a limit register ascertain a logical addresss space
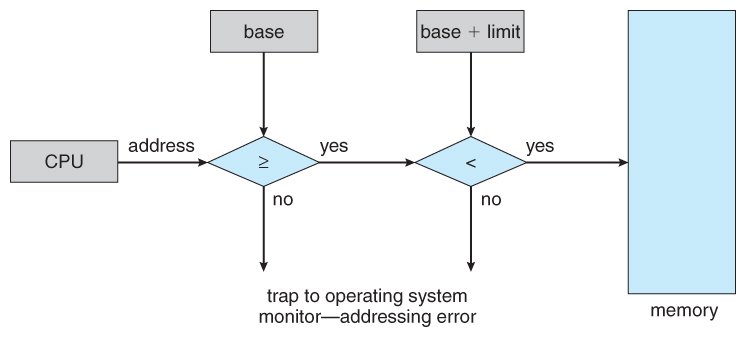
Figure 8.two - Hardware address protection with base and limit registers8.1.ii Address Binding
- User programs typically refer to memory addresses with symbolic names such as "i", "count", and "averageTemperature". These symbolic names must exist mapped or bound to physical retentivity addresses, which typically occurs in several stages:
- Compile Time - If it is known at compile time where a program will reside in physical memory, then absolute code tin can exist generated by the compiler, containing actual physical addresses. However if the load address changes at some later on fourth dimension, then the program will have to be recompiled. DOS .COM programs utilize compile time binding.
- Load Fourth dimension - If the location at which a plan will be loaded is not known at compile time, so the compiler must generate relocatable code , which references addresses relative to the kickoff of the programme. If that starting address changes, then the programme must be reloaded but not recompiled.
- Execution Time - If a program tin be moved around in retention during the grade of its execution, and so binding must be delayed until execution fourth dimension. This requires special hardware, and is the method implemented by near modern OSes.
- Figure 8.three shows the various stages of the binding processes and the units involved in each stage:
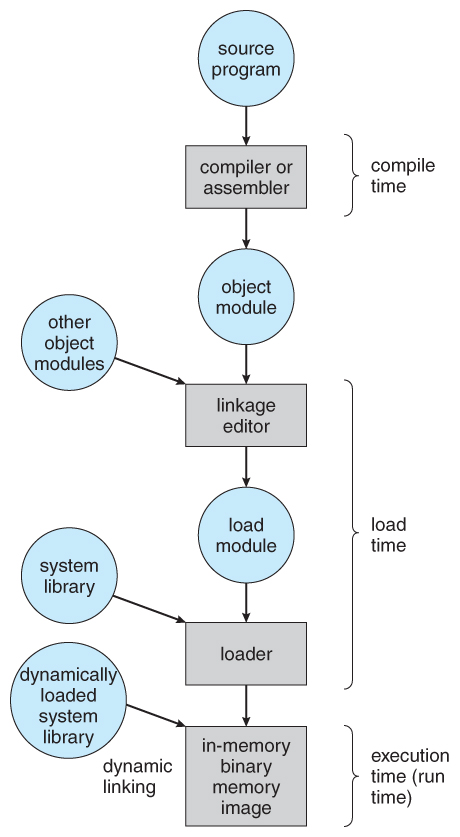
Figure 8.3 - Multistep processing of a user programme8.1.3 Logical Versus Physical Address Infinite
- The address generated by the CPU is a logical address , whereas the address actually seen by the memory hardware is a physical address .
- Addresses spring at compile time or load time accept identical logical and concrete addresses.
- Addresses created at execution time, notwithstanding, accept unlike logical and physical addresses.
- In this case the logical address is also known equally a virtual address , and the two terms are used interchangeably by our text.
- The set of all logical addresses used past a program composes the logical address space , and the set of all corresponding physical addresses composes the physical address space.
- The run time mapping of logical to physical addresses is handled by the retentiveness-management unit of measurement, MMU .
- The MMU can accept on many forms. One of the simplest is a modification of the base-register scheme described earlier.
- The base register is now termed a relocation register , whose value is added to every retentiveness asking at the hardware level.
- Note that user programs never see physical addresses. User programs work entirely in logical accost space, and any memory references or manipulations are done using purely logical addresses. Merely when the address gets sent to the physical retentivity chips is the physical memory accost generated.
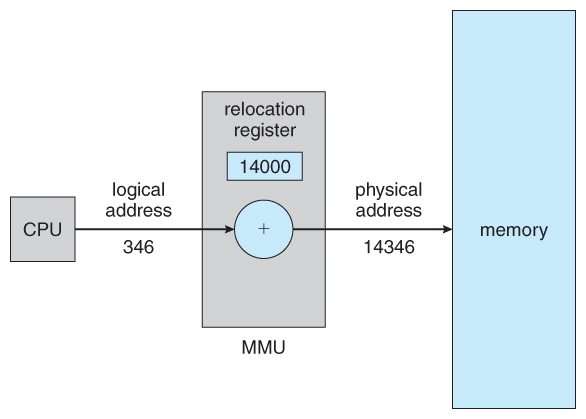
Effigy 8.4 - Dynamic relocation using a relocation registerviii.1.four Dynamic Loading
- Rather than loading an entire program into memory at once, dynamic loading loads upwards each routine as it is called. The advantage is that unused routines need never be loaded, reducing total retention usage and generating faster program startup times. The downside is the added complexity and overhead of checking to see if a routine is loaded every time it is called and then then loading it upwards if it is not already loaded.
8.i.v Dynamic Linking and Shared Libraries
- With static linking library modules get fully included in executable modules, wasting both disk space and main retentiveness usage, because every program that included a sure routine from the library would have to take their own re-create of that routine linked into their executable lawmaking.
- With dynamic linking , however, only a stub is linked into the executable module, containing references to the actual library module linked in at run fourth dimension.
- This method saves disk space, because the library routines do non need to be fully included in the executable modules, only the stubs.
- We will as well larn that if the code department of the library routines is reentrant , ( meaning it does not modify the code while it runs, making it safety to re-enter it ), and then main retentiveness can be saved by loading only one re-create of dynamically linked routines into memory and sharing the lawmaking amidst all processes that are meantime using information technology. ( Each process would have their own copy of the information section of the routines, but that may be small relative to the code segments. ) Plain the OS must manage shared routines in retentivity.
- An added benefit of dynamically linked libraries ( DLLs , also known as shared libraries or shared objects on UNIX systems ) involves easy upgrades and updates. When a program uses a routine from a standard library and the routine changes, then the program must be re-built ( re-linked ) in order to incorporate the changes. However if DLLs are used, then as long as the stub doesn't change, the program tin can be updated only by loading new versions of the DLLs onto the system. Version information is maintained in both the program and the DLLs, so that a program can specify a detail version of the DLL if necessary.
- In practice, the beginning time a program calls a DLL routine, the stub volition recognize the fact and will supercede itself with the actual routine from the DLL library. Further calls to the same routine will admission the routine directly and not incur the overhead of the stub access. ( Following the UML Proxy Design . )
- ( Additional information regarding dynamic linking is available at http://world wide web.iecc.com/linker/linker10.html )
8.2 Swapping
- A process must exist loaded into retention in order to execute.
- If there is not plenty memory available to keep all running processes in retentiveness at the aforementioned time, so some processes who are non currently using the CPU may have their memory swapped out to a fast local disk called the backing store.
8.2.i Standard Swapping
- If compile-time or load-time accost binding is used, then processes must exist swapped back into the same retention location from which they were swapped out. If execution time bounden is used, then the processes can be swapped back into any available location.
- Swapping is a very slow process compared to other operations. For example, if a user procedure occupied x MB and the transfer rate for the backing store were 40 MB per second, then it would have 1/4 second ( 250 milliseconds ) just to do the data transfer. Adding in a latency lag of 8 milliseconds and ignoring head seek time for the moment, and further recognizing that swapping involves moving onetime data out as well as new information in, the overall transfer time required for this swap is 512 milliseconds, or over half a second. For efficient processor scheduling the CPU time slice should be significantly longer than this lost transfer time.
- To reduce swapping transfer overhead, it is desired to transfer every bit footling information as possible, which requires that the arrangement know how much memory a procedure is using, equally opposed to how much it might apply. Programmers can aid with this by freeing up dynamic retentiveness that they are no longer using.
- It is of import to swap processes out of memory merely when they are idle, or more than to the point, only when at that place are no pending I/O operations. ( Otherwise the pending I/O operation could write into the incorrect procedure's retentivity space. ) The solution is to either swap only totally idle processes, or exercise I/O operations just into and out of Os buffers, which are then transferred to or from process'south main memory equally a second step.
- Most modern OSes no longer use swapping, because it is too slow and in that location are faster alternatives available. ( eastward.yard. Paging. ) Even so some UNIX systems will still invoke swapping if the system gets extremely full, and so discontinue swapping when the load reduces once more. Windows three.one would use a modified version of swapping that was somewhat controlled by the user, swapping procedure's out if necessary and then merely swapping them back in when the user focused on that detail window.
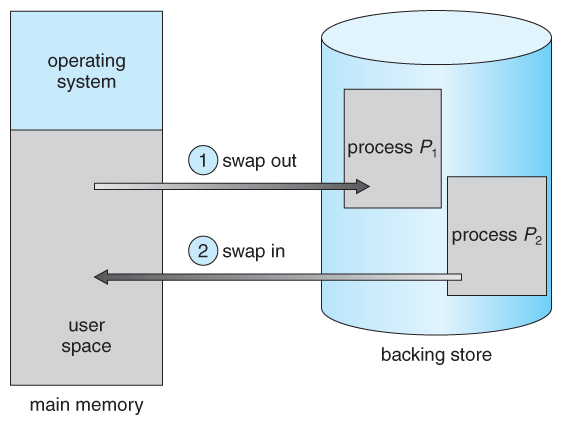
Figure eight.5 - Swapping of two processes using a disk as a backing store
8.2.ii Swapping on Mobile Systems ( New Department in 9th Edition )
- Swapping is typically not supported on mobile platforms, for several reasons:
- Mobile devices typically utilize flash memory in place of more spacious hard drives for persistent storage, and then there is not as much space bachelor.
- Wink memory can only exist written to a limited number of times before it becomes unreliable.
- The bandwidth to flash memory is also lower.
- Apple's IOS asks applications to voluntarily free upward memory
- Read-only data, east.thou. code, is simply removed, and reloaded afterwards if needed.
- Modified data, e.g. the stack, is never removed, but . . .
- Apps that fail to complimentary upwardly sufficient memory can be removed by the OS
- Android follows a similar strategy.
- Prior to terminating a procedure, Android writes its application land to flash memory for quick restarting.
8.3 Contiguous Memory Allotment
- Ane approach to retention management is to load each process into a contiguous space. The operating organisation is allocated space first, usually at either low or loftier retention locations, and so the remaining available retention is allocated to processes as needed. ( The Os is usually loaded depression, because that is where the interrupt vectors are located, but on older systems office of the OS was loaded high to brand more room in low memory ( within the 640K barrier ) for user processes. )
8.3.1 Retention Protection ( was Memory Mapping and Protection )
- The arrangement shown in Figure viii.6 below allows protection against user programs accessing areas that they should non, allows programs to be relocated to dissimilar retention starting addresses every bit needed, and allows the retentiveness space devoted to the Os to abound or shrink dynamically as needs change.
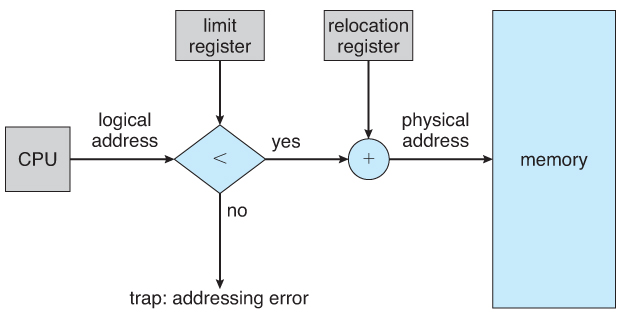
Figure 8.vi - Hardware back up for relocation and limit registersviii.3.2 Retention Allocation
- I method of allocating face-to-face memory is to separate all available retentiveness into equal sized partitions, and to assign each process to their own partition. This restricts both the number of simultaneous processes and the maximum size of each process, and is no longer used.
- An alternate arroyo is to keep a listing of unused ( free ) retentiveness blocks ( holes ), and to find a hole of a suitable size whenever a process needs to exist loaded into memory. There are many different strategies for finding the "best" allocation of retentiveness to processes, including the iii well-nigh unremarkably discussed:
- First fit - Search the listing of holes until ane is found that is big enough to satisfy the request, and assign a portion of that hole to that process. Whatever fraction of the hole non needed by the request is left on the free listing as a smaller hole. Subsequent requests may start looking either from the beginning of the list or from the point at which this search concluded.
- Best fit - Allocate the smallest pigsty that is large enough to satisfy the request. This saves large holes for other procedure requests that may need them later, but the resulting unused portions of holes may be besides small to be of any use, and will therefore be wasted. Keeping the free list sorted tin speed up the process of finding the correct hole.
- Worst fit - Allocate the largest hole available, thereby increasing the likelihood that the remaining portion will be usable for satisfying future requests.
- Simulations bear witness that either first or best fit are better than worst fit in terms of both time and storage utilization. First and all-time fits are about equal in terms of storage utilization, but first fit is faster.
8.three.3. Fragmentation
- All the memory resource allotment strategies endure from external fragmentation , though first and best fits feel the bug more than so than worst fit. External fragmentation means that the available memory is broken up into lots of lilliputian pieces, none of which is big plenty to satisfy the next memory requirement, although the sum total could.
- The corporeality of retentiveness lost to fragmentation may vary with algorithm, usage patterns, and some pattern decisions such equally which end of a hole to allocate and which finish to salvage on the free list.
- Statistical analysis of first fit, for case, shows that for Due north blocks of allocated memory, some other 0.5 N will be lost to fragmentation.
- Internal fragmentation also occurs, with all retention allocation strategies. This is acquired by the fact that memory is allocated in blocks of a stock-still size, whereas the bodily memory needed will rarely be that exact size. For a random distribution of retentivity requests, on the average 1/2 cake volition be wasted per retentiveness request, considering on the average the last allocated cake will exist only half full.
- Note that the same effect happens with difficult drives, and that mod hardware gives us increasingly larger drives and retentiveness at the expense of ever larger block sizes, which translates to more memory lost to internal fragmentation.
- Some systems employ variable size blocks to minimize losses due to internal fragmentation.
- If the programs in retentivity are relocatable, ( using execution-time address binding ), then the external fragmentation problem tin can be reduced via compaction , i.east. moving all processes down to one cease of physical retentiveness. This only involves updating the relocation register for each procedure, every bit all internal piece of work is done using logical addresses.
- Some other solution as we will see in upcoming sections is to allow processes to utilise non-contiguous blocks of concrete memory, with a split relocation annals for each block.
8.iv Segmentation
viii.4.1 Basic Method
- Most users ( programmers ) do non retrieve of their programs as existing in one continuous linear address space.
- Rather they tend to call back of their memory in multiple segments , each dedicated to a particular apply, such every bit code, data, the stack, the heap, etc.
- Memory segmentation supports this view by providing addresses with a segment number ( mapped to a segment base address ) and an offset from the kickoff of that segment.
- For example, a C compiler might generate 5 segments for the user lawmaking, library code, global ( static ) variables, the stack, and the heap, as shown in Figure 8.vii:
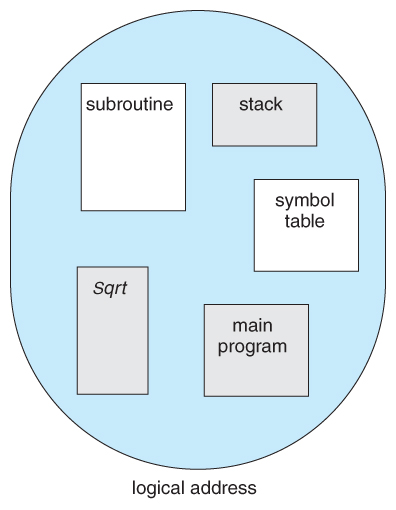
Figure 8.7 Programmer'due south view of a program.
8.4.ii Segmentation Hardware
- A segment tabular array maps segment-offset addresses to physical addresses, and simultaneously checks for invalid addresses, using a organisation similar to the page tables and relocation base registers discussed previously. ( Notation that at this point in the discussion of sectionalization, each segment is kept in contiguous retentivity and may be of different sizes, simply that segmentation can also be combined with paging every bit we shall run into presently. )
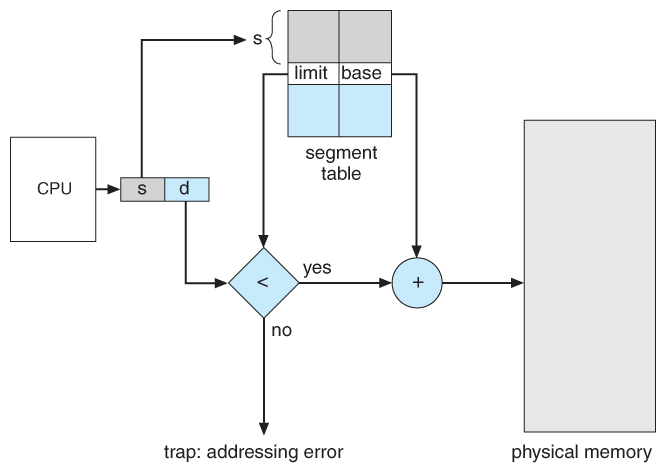
Figure 8.eight - Sectionalisation hardware
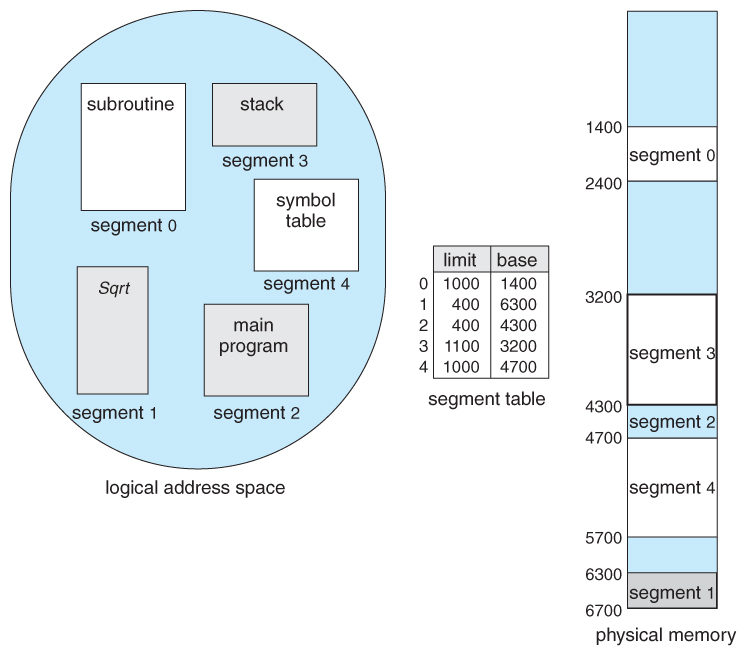
Figure 8.9 - Instance of segmentation
viii.five Paging
- Paging is a memory management scheme that allows processes physical memory to be discontinuous, and which eliminates bug with fragmentation by allocating memory in equal sized blocks known as pages .
- Paging eliminates most of the problems of the other methods discussed previously, and is the predominant retentiveness management technique used today.
8.5.1 Basic Method
- The basic thought behind paging is to divide physical retentiveness into a number of equal sized blocks called frames , and to divide a programs logical retentiveness space into blocks of the same size chosen pages.
- Any page ( from whatever procedure ) tin can be placed into whatsoever available frame.
- The folio table is used to await up what frame a item page is stored in at the moment. In the post-obit example, for instance, page 2 of the programme's logical memory is currently stored in frame 3 of concrete memory:
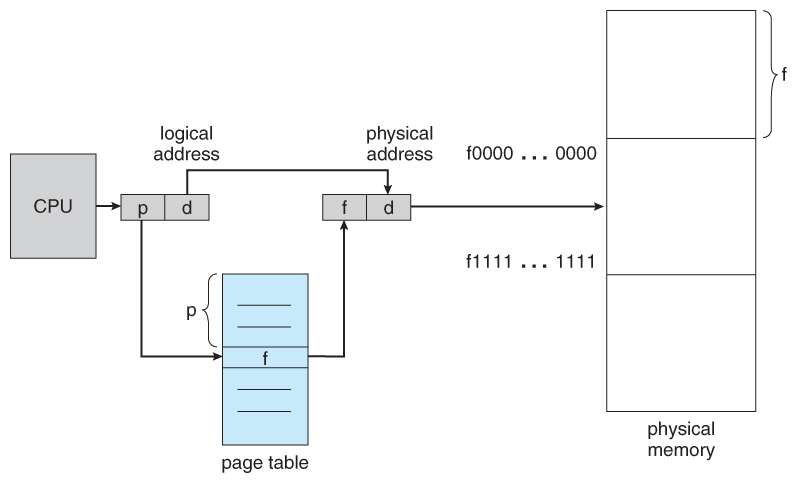
Effigy 8.x - Paging hardware
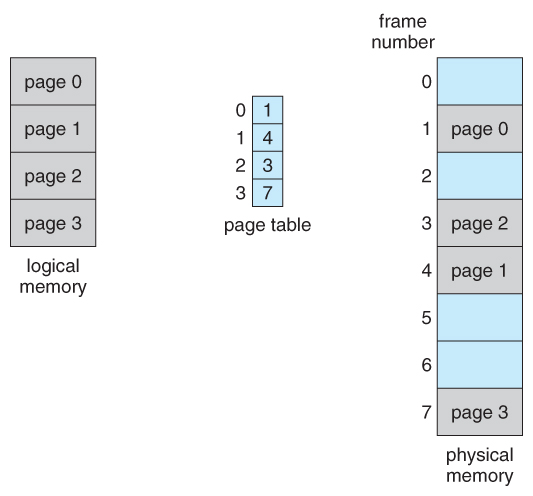
Figure 8.11 - Paging model of logical and physical retention
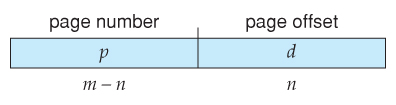
- A logical address consists of 2 parts: A folio number in which the accost resides, and an offset from the beginning of that page. ( The number of bits in the page number limits how many pages a single process can address. The number of bits in the offset determines the maximum size of each folio, and should represent to the system frame size. )
- The page table maps the folio number to a frame number, to yield a physical address which also has two parts: The frame number and the offset within that frame. The number of bits in the frame number determines how many frames the organization tin can accost, and the number of bits in the offset determines the size of each frame.
- Page numbers, frame numbers, and frame sizes are determined by the compages, simply are typically powers of two, assuasive addresses to be carve up at a certain number of bits. For case, if the logical address size is 2^1000 and the page size is 2^n, then the high-order g-n bits of a logical address designate the page number and the remaining northward bits represent the offset.
- Note also that the number of bits in the page number and the number of bits in the frame number do non take to be identical. The sometime determines the address range of the logical address infinite, and the latter relates to the physical accost space.
- ( DOS used to use an addressing scheme with 16 bit frame numbers and 16-bit offsets, on hardware that just supported 24-scrap hardware addresses. The result was a resolution of starting frame addresses finer than the size of a single frame, and multiple frame-offset combinations that mapped to the same physical hardware address. )
- Consider the post-obit micro instance, in which a procedure has 16 bytes of logical memory, mapped in iv byte pages into 32 bytes of physical retention. ( Presumably some other processes would exist consuming the remaining 16 bytes of physical memory. )
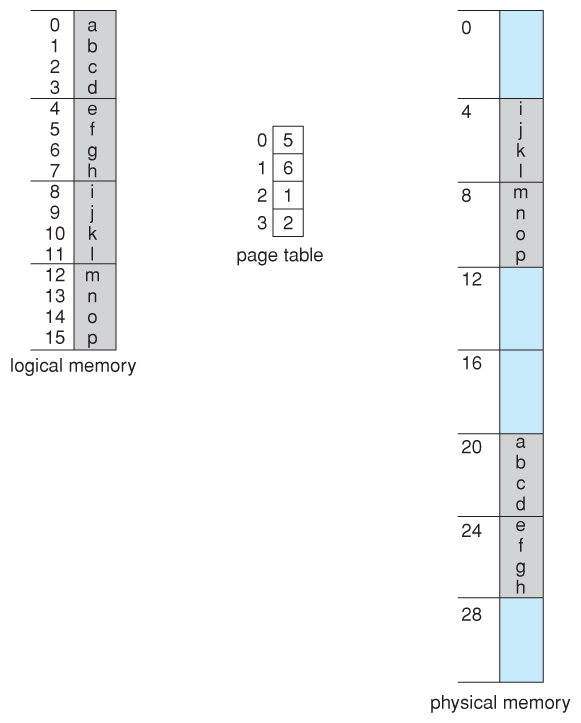
Figure viii.12 - Paging example for a 32-byte memory with iv-byte pages
- Notation that paging is similar having a table of relocation registers, one for each folio of the logical memory.
- At that place is no external fragmentation with paging. All blocks of physical memory are used, and at that place are no gaps in between and no problems with finding the right sized hole for a item chunk of retentiveness.
- There is, all the same, internal fragmentation. Memory is allocated in chunks the size of a page, and on the average, the last folio will merely be half full, wasting on the average half a folio of memory per process. ( Mayhap more, if processes continue their lawmaking and data in separate pages. )
- Larger page sizes waste more memory, but are more efficient in terms of overhead. Modernistic trends have been to increase folio sizes, and some systems even take multiple size pages to try and make the all-time of both worlds.
- Folio tabular array entries ( frame numbers ) are typically 32 bit numbers, allowing access to 2^32 concrete folio frames. If those frames are 4 KB in size each, that translates to 16 TB of addressable physical memory. ( 32 + 12 = 44 bits of physical address infinite. )
- When a process requests memory ( east.g. when its code is loaded in from disk ), costless frames are allocated from a free-frame listing, and inserted into that procedure's folio tabular array.
- Processes are blocked from accessing anyone else's retention because all of their memory requests are mapped through their page tabular array. In that location is no way for them to generate an address that maps into whatsoever other process's retentiveness space.
- The operating arrangement must continue track of each private process's folio tabular array, updating it whenever the process's pages get moved in and out of memory, and applying the correct page table when processing organization calls for a particular procedure. This all increases the overhead involved when swapping processes in and out of the CPU. ( The currently agile folio table must be updated to reflect the process that is currently running. )
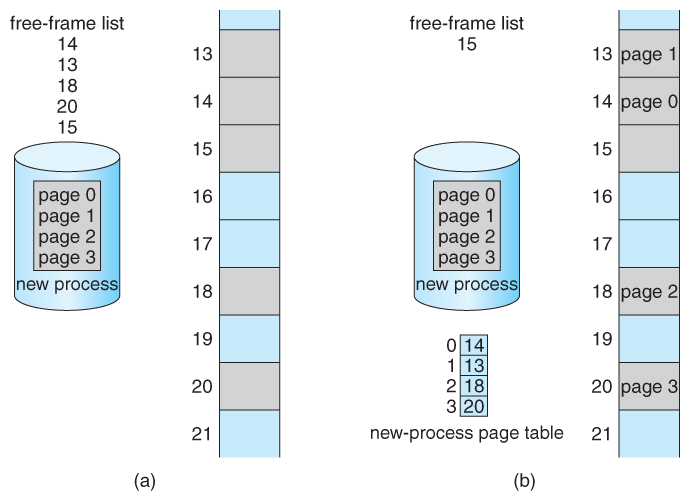
Figure eight.thirteen - Free frames (a) earlier allotment and (b) afterwards allocationviii.5.2 Hardware Support
- Page lookups must be washed for every memory reference, and whenever a process gets swapped in or out of the CPU, its page table must be swapped in and out too, along with the education registers, etc. Information technology is therefore appropriate to provide hardware back up for this operation, in order to make it as fast every bit possible and to make process switches as fast equally possible also.
- I pick is to use a gear up of registers for the page table. For example, the DEC PDP-11 uses 16-bit addressing and eight KB pages, resulting in simply viii pages per procedure. ( It takes xiii bits to address 8 KB of offset, leaving only 3 bits to ascertain a page number. )
- An alternating option is to shop the page table in main memory, and to use a unmarried register ( called the folio-table base register, PTBR ) to record where in retentivity the page tabular array is located.
- Process switching is fast, considering merely the single annals needs to be changed.
- All the same retentivity access just got one-half equally fast, because every retention access now requires two memory accesses - Ane to fetch the frame number from memory and then another ane to access the desired memory location.
- The solution to this problem is to utilise a very special high-speed memory device called the translation wait-bated buffer, TLB.
- The benefit of the TLB is that it tin search an unabridged table for a key value in parallel, and if information technology is plant anywhere in the table, then the corresponding lookup value is returned.
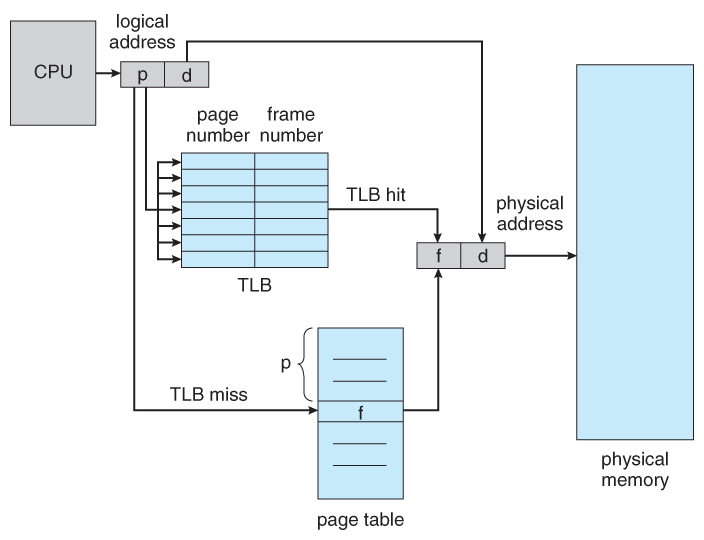
Figure 8.fourteen - Paging hardware with TLB
- The TLB is very expensive, notwithstanding, and therefore very modest. ( Non large enough to concur the entire page table. ) It is therefore used as a cache device.
- Addresses are kickoff checked against the TLB, and if the info is non there ( a TLB miss ), and so the frame is looked upwards from main retentiveness and the TLB is updated.
- If the TLB is full, and then replacement strategies range from least-recently used, LRU to random.
- Some TLBs let some entries to be wired downwardly , which means that they cannot be removed from the TLB. Typically these would be kernel frames.
- Some TLBs store address-space identifiers, ASIDs , to keep rail of which procedure "owns" a item entry in the TLB. This allows entries from multiple processes to be stored simultaneously in the TLB without granting one procedure admission to another process's memory location. Without this feature the TLB has to be flushed clean with every procedure switch.
- The percentage of time that the desired information is found in the TLB is termed the hit ratio .
- ( Eighth Edition Version: ) For example, suppose that information technology takes 100 nanoseconds to access master retention, and simply 20 nanoseconds to search the TLB. Then a TLB hit takes 120 nanoseconds total ( 20 to notice the frame number so another 100 to go get the data ), and a TLB miss takes 220 ( 20 to search the TLB, 100 to go get the frame number, and and so some other 100 to go become the data. ) So with an eighty% TLB hit ratio, the boilerplate memory admission time would be:
0.80 * 120 + 0.20 * 220 = 140 nanoseconds
for a 40% slowdown to get the frame number. A 98% hit rate would yield 122 nanoseconds boilerplate access time ( you should verify this ), for a 22% slowdown.
- ( Ninth Edition Version: ) The ninth edition ignores the 20 nanoseconds required to search the TLB, yielding
0.80 * 100 + 0.20 * 200 = 120 nanoseconds
for a 20% slowdown to get the frame number. A 99% striking rate would yield 101 nanoseconds average access time ( you lot should verify this ), for a 1% slowdown.
8.5.3 Protection
- The page table can also aid to protect processes from accessing memory that they shouldn't, or their own memory in ways that they shouldn't.
- A bit or bits can exist added to the folio tabular array to classify a page as read-write, read-only, read-write-execute, or some combination of these sorts of things. And so each memory reference can exist checked to ensure it is accessing the memory in the appropriate manner.
- Valid / invalid $.25 can be added to "mask off" entries in the page table that are not in use by the current procedure, as shown past instance in Figure 8.12 below.
- Note that the valid / invalid bits described above cannot block all illegal retentivity accesses, due to the internal fragmentation. ( Areas of memory in the last folio that are non entirely filled by the process, and may contain data left over by whoever used that frame final. )
- Many processes practise not utilize all of the folio table available to them, especially in modern systems with very large potential page tables. Rather than waste memory by creating a full-size folio table for every procedure, some systems use a page-table length register, PTLR , to specify the length of the page table.
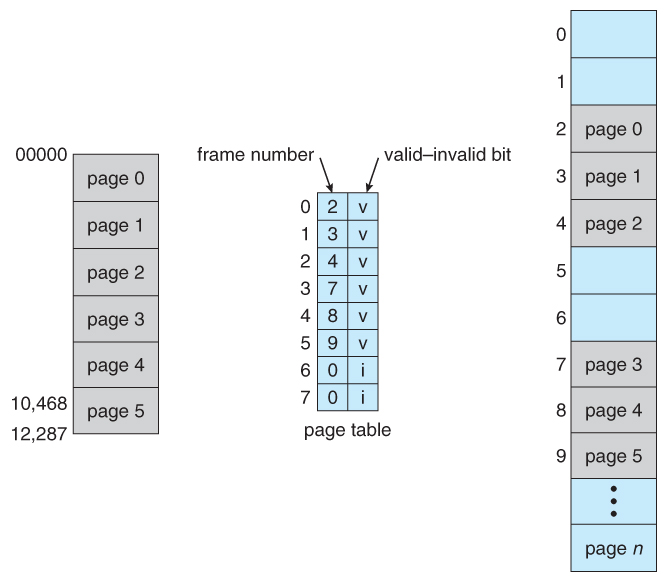
Figure viii.15 - Valid (five) or invalid (i) flake in page table8.five.4 Shared Pages
- Paging systems can go far very easy to share blocks of memory, past simply duplicating page numbers in multiple page frames. This may be done with either code or data.
- If code is reentrant , that means that it does non write to or change the code in any fashion ( it is non self-modifying ), and information technology is therefore safe to re-enter it. More chiefly, it means the lawmaking can be shared by multiple processes, and so long as each has their own copy of the data and registers, including the instruction register.
- In the example given below, three different users are running the editor simultaneously, only the lawmaking is only loaded into memory ( in the page frames ) ane fourth dimension.
- Some systems as well implement shared memory in this fashion.
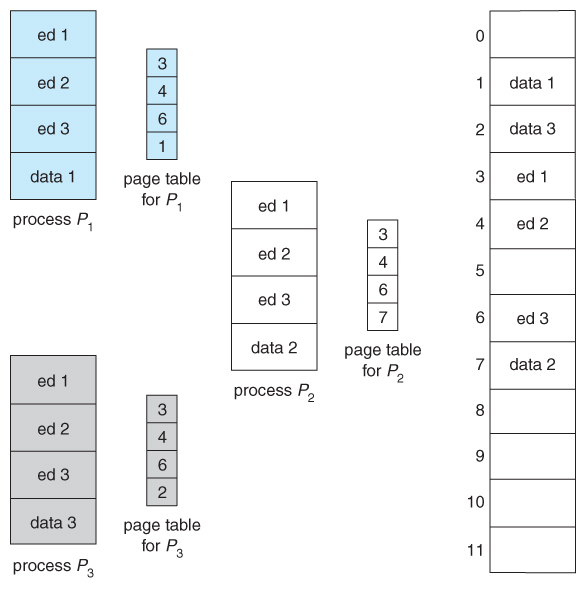
Effigy 8.sixteen - Sharing of lawmaking in a paging environment
eight.6 Construction of the Page Table
eight.half dozen.1 Hierarchical Paging
- Nearly modern computer systems support logical accost spaces of 2^32 to 2^64.
- With a ii^32 address space and 4K ( 2^12 ) page sizes, this exit 2^20 entries in the page tabular array. At 4 bytes per entry, this amounts to a 4 MB page table, which is too big to reasonably keep in contiguous retention. ( And to swap in and out of retentivity with each process switch. ) Annotation that with 4K pages, this would take 1024 pages just to hold the folio table!
- One option is to use a 2-tier paging system, i.e. to page the page tabular array.
- For case, the 20 bits described above could exist broken down into two 10-bit page numbers. The first identifies an entry in the outer folio table, which identifies where in memory to find i page of an inner page table. The second ten bits finds a specific entry in that inner page table, which in turn identifies a particular frame in concrete memory. ( The remaining 12 bits of the 32 bit logical address are the commencement inside the 4K frame. )
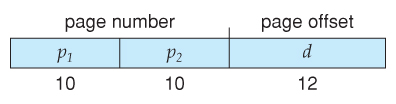
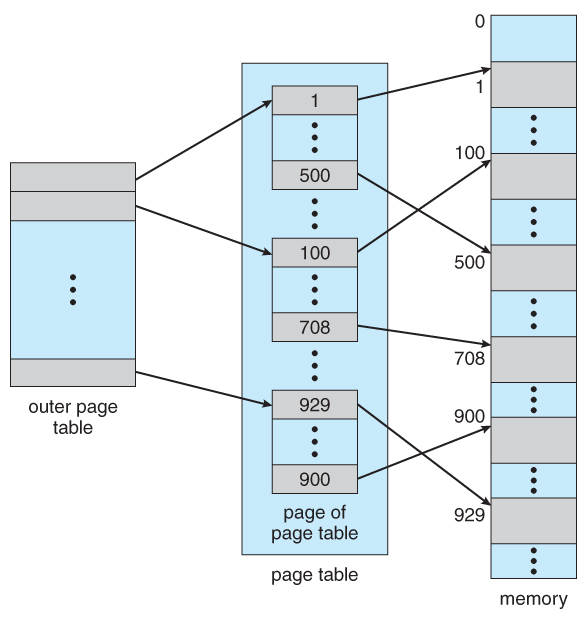
Figure viii.17 A two-level page-tabular array scheme
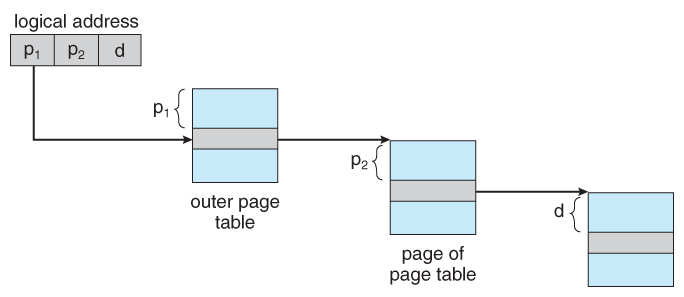
Figure 8.xviii - Accost translation for a two-level 32-bit paging architecture
- VAX Architecture divides 32-bit addresses into four equal sized sections, and each page is 512 bytes, yielding an address class of:
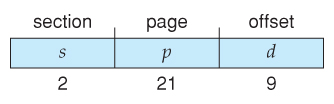
- With a 64-flake logical address space and 4K pages, there are 52 $.25 worth of page numbers, which is still also many even for ii-level paging. Ane could increase the paging level, but with 10-scrap folio tables it would have 7 levels of indirection, which would be prohibitively tedious retentivity admission. So another approach must be used.
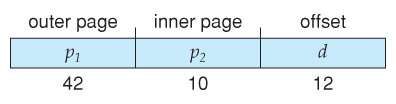
64-bits Ii-tiered leaves 42 bits in outer tabular array
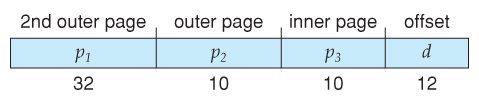
Going to a fourth level nonetheless leaves 32 $.25 in the outer table.
8.6.two Hashed Page Tables
- One common data structure for accessing data that is sparsely distributed over a broad range of possible values is with hash tables . Figure 8.16 beneath illustrates a hashed page table using concatenation-and-bucket hashing:
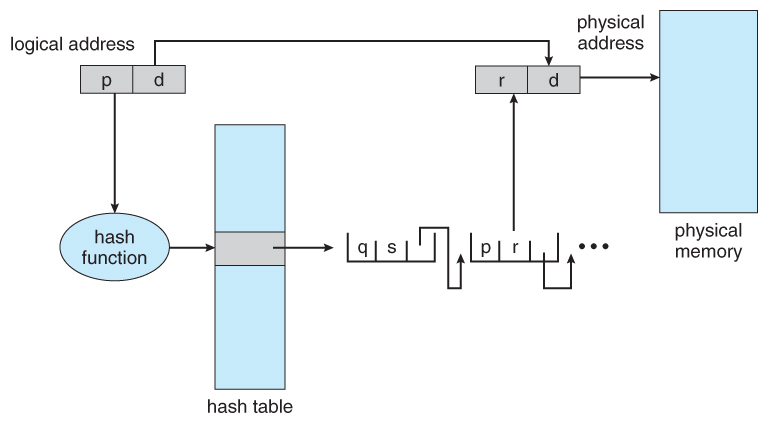
Figure 8.19 - Hashed page tableeight.6.3 Inverted Page Tables
- Another approach is to use an inverted folio tabular array . Instead of a table listing all of the pages for a item process, an inverted folio tabular array lists all of the pages currently loaded in memory, for all processes. ( I.e. there is one entry per frame instead of one entry per folio . )
- Access to an inverted folio tabular array tin can be slow, every bit it may be necessary to search the entire table in order to detect the desired page ( or to discover that it is not at that place. ) Hashing the table can help speedup the search process.
- Inverted page tables prohibit the normal method of implementing shared retention, which is to map multiple logical pages to a common concrete frame. ( Because each frame is now mapped to one and only i process. )
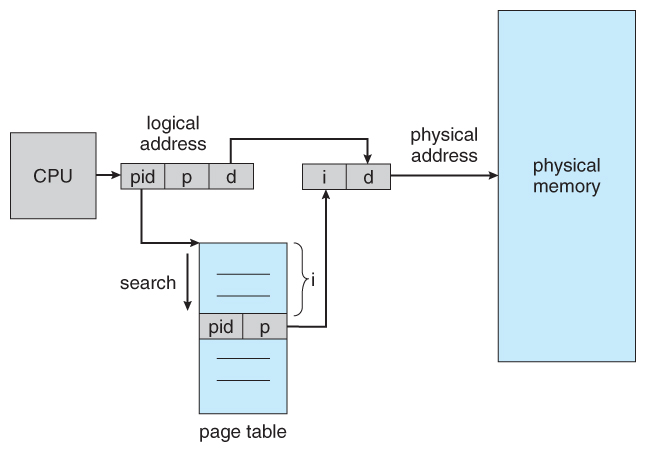
Figure 8.20 - Inverted page table
viii.half-dozen.4 Oracle SPARC Solaris ( Optional, New Section in 9th Edition )
8.7 Example: Intel 32 and 64-scrap Architectures ( Optional )
8.7.ane.1 IA-32 Segmentation
- The Pentium CPU provides both pure segmentation and segmentation with paging. In the latter case, the CPU generates a logical accost ( segment-outset pair ), which the partition unit converts into a logical linear accost, which in turn is mapped to a physical frame by the paging unit, as shown in Effigy eight.21:
![]()
Figure 8.21 - Logical to concrete address translation in IA-32
viii.7.one.1 IA-32 Sectionalisation
- The Pentium architecture allows segments to be as large equally iv GB, ( 24 bits of get-go ).
- Processes can have equally many equally 16K segments, divided into two 8K groups:
- 8K private to that particular process, stored in the Local Descriptor Table, LDT.
- 8K shared amid all processes, stored in the Global Descriptor Table, GDT.
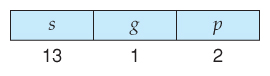
- Logical addresses are ( selector, first ) pairs, where the selector is made up of sixteen bits:
- A 13 fleck segment number ( up to 8K )
- A 1 bit flag for LDT vs. GDT.
- 2 $.25 for protection codes.
- The descriptor tables contain 8-byte descriptions of each segment, including base and limit registers.
- Logical linear addresses are generated by looking the selector up in the descriptor table and adding the appropriate base accost to the start, equally shown in Figure 8.22:
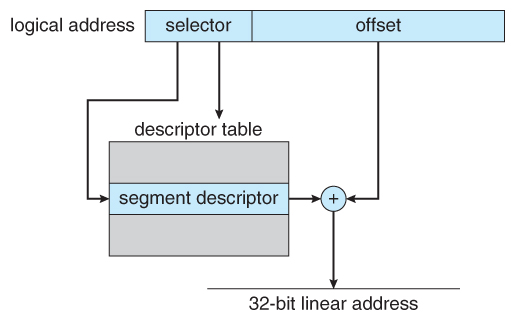
Effigy 8.22 - IA-32 partitionviii.7.1.2 IA-32 Paging
- Pentium paging unremarkably uses a two-tier paging scheme, with the outset 10 $.25 existence a page number for an outer page table ( a.chiliad.a. page directory ), and the next 10 bits being a page number within 1 of the 1024 inner page tables, leaving the remaining 12 bits every bit an outset into a 4K page.
- A special scrap in the page directory can indicate that this folio is a 4MB page, in which case the remaining 22 bits are all used as outset and the inner tier of folio tables is not used.
- The CR3 register points to the folio directory for the current procedure, every bit shown in Figure 8.23 below.
- If the inner page table is currently swapped out to deejay, then the page directory will have an "invalid chip" set, and the remaining 31 bits provide information on where to find the swapped out page table on the deejay.
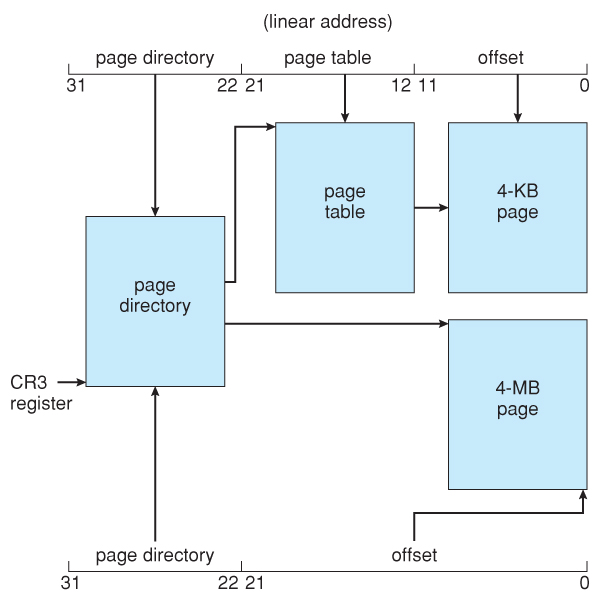
Figure 8.23 - Paging in the IA-32 architecture.
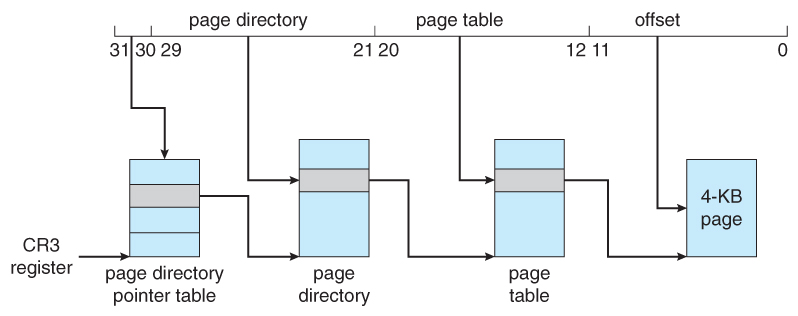
Figure 8.24 - Page address extensions.8.7.2 x86-64

Effigy 8.25 - x86-64 linear accost.
8.8 Example: ARM Architecture ( Optional )
![]()
Figure 8.26 - Logical accost translation in ARM.
Old viii.7.3 Linux on Pentium Systems - Omitted from the 9th Edition
- Because Linux is designed for a wide diversity of platforms, some of which offer merely express support for partition, Linux supports minimal segmentation. Specifically Linux uses only 6 segments:
- Kernel code.
- Kerned data.
- User code.
- User data.
- A task-country segment, TSS
- A default LDT segment
- All processes share the aforementioned user code and data segments, considering all process share the aforementioned logical address space and all segment descriptors are stored in the Global Descriptor Table. ( The LDT is generally not used. )
- Each process has its ain TSS, whose descriptor is stored in the GDT. The TSS stores the hardware country of a process during context switches.
- The default LDT is shared past all processes and by and large not used, but if a process needs to create its ain LDT, it may do then, and use that instead of the default.
- The Pentium architecture provides 2 bits ( iv values ) for protection in a segment selector, but Linux only uses two values: user mode and kernel mode.
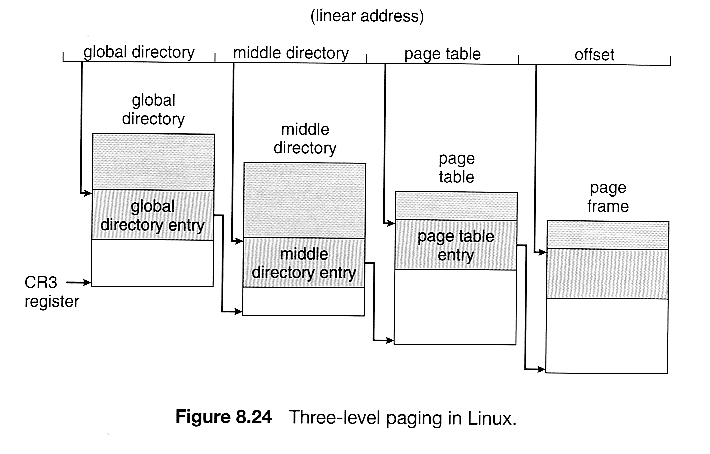
- Because Linux is designed to run on 64-chip also as 32-bit architectures, it employs a three-level paging strategy as shown in Effigy eight.24, where the number of $.25 in each portion of the address varies past architecture. In the case of the Pentium architecture, the size of the middle directory portion is set to 0 $.25, effectively bypassing the middle directory.

8.8 Summary
-
( For a fun and easy explanation of paging, y'all may want to read about The Paging Game. )

If The Relocation Register Holds The Value -83968.how Many Kilobytes Was It Moved?,
Source: https://www.cs.uic.edu/~jbell/CourseNotes/OperatingSystems/8_MainMemory.html
Posted by: swinkcade1947.blogspot.com
0 Response to "If The Relocation Register Holds The Value -83968.how Many Kilobytes Was It Moved?"
Post a Comment